
Onderzoeker Dan Ariely moet hebben gesjoemeld bij zijn pogingen mensen de waarheid te laten opschrijven.

door Pepijn van Erp – Skepter 34.4 (2021)
‘VEEL van wat wetenschappers dachten te weten over liegen en eerlijkheid blijkt bij nader inzien toch anders te liggen,’ schreef Ronald Veldhuizen een jaar geleden in Skepter. In zijn stuk kwam onder meer onderzoek van Dan Ariely uit 2012 aan de orde, waaruit moest blijken dat mensen eerlijker antwoorden als je ze vooraf een eerlijkheidsheidsverklaring laat tekenen.
Een uitgebreide replicatie van dat onderzoek — waaraan Ariely en collega’s meewerkten — liet echter geen enkel effect zien. Niet leuk voor Ariely, maar zo kan het gaan in de wetenschap. Hij zei alweer plannen te hebben om de eerlijkheidsheidsverklaring, waarin hij nog steeds vertrouwen had, op andere manieren te onderzoeken.
Toch was het wel opmerkelijk dat er eerst zo’n groot effect wordt gevonden, en in de replicatie geen enkel.
Dat vond ook een groepje ‘datadetectives’: zij besloten nog eens goed te kijken naar een van de experimenten uit Ariely’s oorspronkelijke artikel, studie nummer 3. Ze deelden hun bevindingen in augustus dit jaar via Datacolada.org, het blog van onder andere Uri Simonsohn, de man die jaren terug de fraude van Dirk Smeesters aantoonde.
Gereden mijlen
Studie 3 was gebaseerd op data die in samenwerking met een autoverzekeringsbedrijf waren verkregen. Verzekerden moeten eens in de zoveel tijd op een formulier de kilometerstand van hun auto’s invullen. De indeling van het formulier werd onderdeel van het experiment. Bij de ene groep stond de verklaring ‘I promise that the information I am providing is true’ zoals gebruikelijk onderaan het formulier, bij de andere groep had Ariely die bovenaan laten zetten.
De uitkomst was dat de groep die bovenaan moest tekenen zo’n 10 procent meer gereden mijlen meldde: 26.100 tegen 23.700. Dat duidde er volgens Ariely op dat ze eerlijker waren geweest. Immers, meer kilometers rijden betekent een grotere kans op een ongeluk en dus een hogere premie.
Ondanks wat beperkingen een interessante studie, vooral ook omdat het was gebaseerd op data uit de echte wereld en niet, zoals zoveel ander onderzoek op dit gebied, uit een gekunsteld experiment met psychologiestudenten. En het was ook nog eens een flinke berg data: 13 488 ingevulde verzekeringsformulieren voor 20 741 voertuigen.
Tijdens de replicatie was er overigens al iets raars in de cijfers ontdekt. De gemiddelde stand op de tellers verschilde aan het begin al enorm: 59 700 mijl in de groep die bovenaan ondertekende en 75 000 mijl in de andere groep — terwijl die standen toch maanden of jaren voor het experiment waren ingevuld. De onderzoekers vermoedden dat de groepen niet helemaal willekeurig waren ingedeeld, en lieten het daarbij. Wel stelden ze de ruwe data van zowel hun eigen replicatie als die van studie 3 beschikbaar. Met die laatste gingen nieuwsgierige onderzoekers aan de slag.
Uniform
Op het formulier hadden de verzekerden alleen de huidige stand hoeven invullen — de verzekeringsmaatschappij kende immers de stand van de vorige meting. De tijd tussen deze metingen verschilde uiteraard sterk per auto. Toch kun je wel iets zeggen over de verdeling van de afgelegde kilometers per auto: er zullen weinig auto’s zijn met heel weinig of heel veel mijlen, en juist vrij veel die rond het gemiddelde zitten.
Dat bleek echter in de data van Ariely niet het geval. De verdeling in zijn onderzoek bleek nagenoeg uniform, dus voor elke berekende afgelegde afstand ongeveer evenveel auto’s. De afgelegde afstand vertoonde bovendien een abrupte grens: er reden ruim 1300 klanten met hun favoriete auto tussen de 40.000 en 45.000 mijl en een vergelijkbaar aantal tussen de 45.000 en 50.000 mijl, maar niemand had meer dan 50.000 mijl gereden. Ook voor de tweede, derde en vierde auto van de verzekerden bleek dit op te gaan.
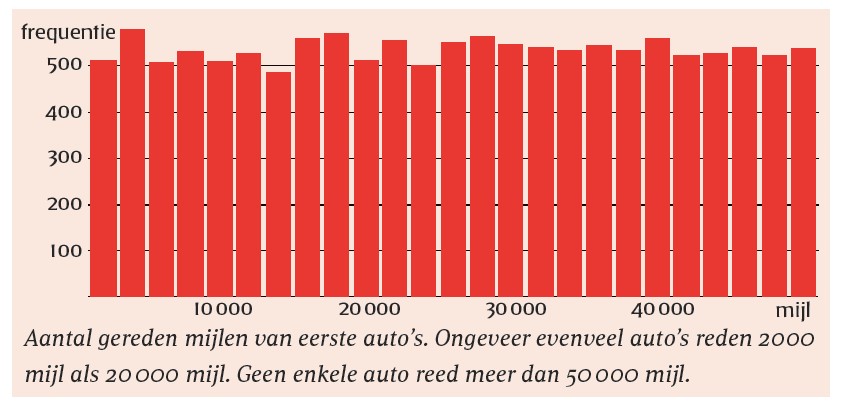
Deze observatie is eigenlijk al genoeg om de conclusie te trekken dat de data niet deugen. Het is bijzonder lastig om een geloofwaardig scenario te verzinnen waarop ze door eerlijke vergissingen tot stand zijn gekomen. Maar dit was niet alles.
Afronden
Als je mensen vraagt een groot getal af te lezen van een teller en in te vullen op een formulier, zullen veel mensen afronden. Van 31.198 maak je dan 31.200 of zelfs 31.000. Het gevolg is dat veelvouden van 500 of 1000 naar verwachting vaker optreden. Dat bleek inderdaad het geval bij de eerste meting, maar niet bij de tweede. Ook de laatste cijfers van de tellers waren daar zo gelijk verdeeld als het maar kan. Dit duidt erop dat ze met de computer zijn geproduceerd. Meer aanwijzingen voor manipulatie vonden de datadetectives toen het hun opviel dat in de kolom met de oude kilometerstanden (die dus vóór het experiment al bekend waren bij de verzekeraar) er precies evenveel getallen staan in het lettertype Calibri als in het lettertype Cambria.

Dat er verschillende lettertypes zijn gebruikt, is op zichzelf wel apart, maar nog niet direct verdacht. Dat wordt het wel als die twee groepen vrijwel exacte kopieën van elkaar zijn: voor elke ‘Calibri-klant’ is een ‘Cambria-klant’ te vinden die er heel erg op lijkt: de tellerstanden voor alle auto’s per klant verschillen slechts een klein, willekeurig aantal mijlen. Het vermoeden rijst dat de dataset verdubbeld is en dat op die tweede verzameling bij alle beginstanden van de tellers steeds een klein random getal is opgeteld. De eindcijfers van de getallen in deze groepen apart bevestigen dat vermoeden: in de Calibri-groep zie je de nul als eindcijfer vaker optreden dan andere cijfers, zoals je verwacht bij echte data, maar bij de Cambria-groep ziet het er weer veel te random uit om geloofwaardig te zijn.
Samengevat komt het erop neer dat het nagenoeg zeker is dat de dataset gemaakt is door een bestaande dataset met tellerstanden te kopiëren, bij de gekopieerde cijfers telkens een willekeurig getal op te tellen, en er vervolgens gefingeerde eindstanden aan toe te voegen.

Enige
Correspondentie van Datacolada met de oorspronkelijke auteurs wees uit dat Ariely eigenlijk als enige deze database in Excel heeft bewerkt. Dat geeft hij zelf ook toe. Hij beweert echter deze data zo van de verzekeraar te hebben gekregen en die niet voldoende gecontroleerd te hebben. Hij zei geen contacten meer te hebben bij de verzekeraar, waarvan hij de naam niet kon noemen vanwege afspraken omtrent vertrouwelijkheid.
De website Buzzfeed is er inmiddels achter om welke verzekeraar het gaat: The Hartford. Die kon bij navraag wel achterhalen dat er een klein project was gedaan met Ariely, maar welke data daarbij waren geleverd, was niet meer terug te vinden. Ariely was in antwoorden op vragen van Buzzfeed ook behoorlijk vaag van wanneer de data waren — hij hield het op 2010 of 2011, maar hij noemde zijn telleronderzoek al eens in een praatje in juli 2008.
Alle auteurs van het artikel erkennen dat de data in dit onderdeel van hun artikel frauduleus lijken. Zij hebben de Proceedings of the National Academy of Sciences gevraagd het artikel in te trekken, wat in september geschiedde.
Intussen liggen andere onderzoeken van Ariely natuurlijk ook onder een vergrootglas. Duke University, waar Ariely hoogleraar is, schakelde het Office of Research Integrity in. Dat heeft in deze kwestie in ieder geval met hem gesproken over de herkomst van de data, maar of er nu een formeel onderzoek wegens fraude naar hem loopt, wil het bureau ontkennen noch bevestigen. Tegenover Buzzfeed betoonde Ariely zich niet al te bezorgd om zijn reputatie: ‘I think that science works over time and things fix themselves.’ We zullen zien hoe dat voor hem uitpakt.
Datacolada: Evidence of fraud in an influential field experiment about dishonesty. Datacolada.org/98.
Uit: Skepter 34.4 (2021)
Naschrift 17 juni 2023
Intussen blijkt er ook met de eerste studie van het artikel wat mis. Hier is de data afkomstig van Francesca Gino, hoogleraar aan de Harvard Business School: “Two different people independently faked data for two different studies in a paper about dishonesty.”




{kind=link}