
‘Te dom om te zien hoe dom ze zijn’
Het ‘dunning-kruger-effect’ wordt te pas en te onpas gebruikt om mensen hun onkunde nog eens flink in te wrijven. Bestaat het effect — en als het bestaat, hoe groot is het dan werkelijk?
door Pepijn van Erp – Skepter 33.1 (2020)
JE komt ze nogal eens tegen: types die stellige meningen verkondigen over een onderwerp waar ze duidelijk weinig vanaf weten, die vol overtuiging ingaan tegen alles wat wetenschappelijk bekend is. Onzinnige antivaccinatiepropaganda, waarschuwingen voor gezondheidsrisico’s van mobiele telefoons, of quasiverklaringen die berusten op kletskoek over kwantummechanica. Bloedirritant soms. Hoe verleidelijk is het dan niet om zo iemand de oren te wassen door zijn onkunde met echte, betrouwbare kennis aan te tonen? En ze ter afsluiting een mokerslag uit te delen door ze toe te voegen dat het hier weer om een ‘typisch geval van Dunning-Kruger’ gaat? Plaatje van internet erbij en klaar. Het is duidelijk dat jouw gesprekspartner op ‘Mount Stupid’ zit!
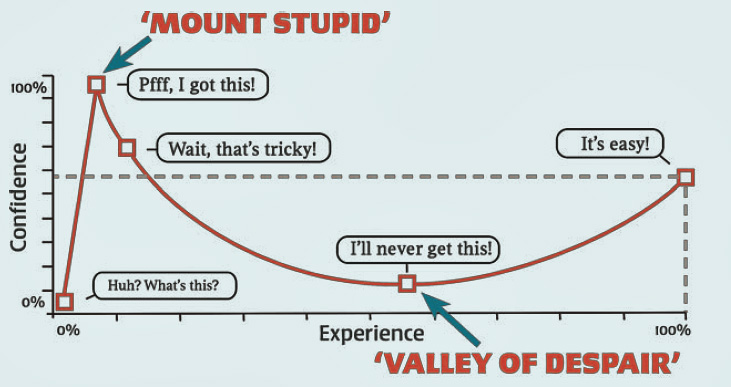
Het dunning-krugereffect bestaat nog niet zo lang onder die naam, een jaar of twintig, maar toch is het al een aardig ingeburgerd begrip. Op internet kom je het om de haverklap tegen op platforms waar stevig gediscussieerd wordt. Het is intussen een standaardwapen in de gereedschapskist met discussietrucs.
Experimenten
Het effect van Dunning en Kruger werd geboren in 1999, toen Justin Kruger en David Dunning, verbonden aan Cornell, hun artikel ‘Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments’ publiceerden. Eigenlijk zouden we van het kruger-dunningeffect moeten spreken, want Kruger was de eerste auteur van het artikel en zal als promovendus bij Dunning het merendeel van het werk gedaan hebben.
In hun artikel beschrijven ze vier experimenten, uitgevoerd onder psychologiestudenten. De studenten kregen tests waarmee hun gevoel voor humor, kennis van de grammatica en logisch redeneren werd gemeten. (Bij humor moesten ze dertig grappen even leuk vinden als een panel van zeven komieken, bij ‘logisch redeneren’ ging het om vraagstukken van het soort ‘in welk huis woont de electricien?’). Telkens werd de studenten gevraagd hoe goed ze dachten de opdrachten uitgevoerd te hebben, en die verwachting werd vergeleken met hun feitelijke score.

Over en onder
Al langer is bekend dat mensen hun competentie vaak wat overschatten. Dat leidt tot het flauwe grapje dat de meeste mensen denken beter dan gemiddeld te scoren. Maar uit de experimenten van Kruger en Dunning kwam iets anders naar voren: niet alleen bleken de mensen met de hoogste scores eerder aan zelfonderschatting te lijden, maar ook was de zelfoverschatting van de minder competente proefpersonen in verhouding veel prominenter aanwezig (figuur 1).
Het zal, terzijde, meteen opvallen dat deze grafieken weinig lijken op de plaatjes waarmee men elkaar op internet om de oren slaat. Er is geen ‘Mount Stupid’, noch een ‘Valley of Despair’.
Hoe zitten deze grafieken precies in elkaar? Kruger en Dunning maakten eerst een indeling in vier groepen op basis van de feitelijke score op de testen en bepaalden daarvan het gemiddelde. Die vier getallen liggen op de groene lijn: het kwart met de laagste scores links, het kwart van de studenten met de hoogste scores rechts. Per groep berekenden ze vervolgens het gemiddelde van de door de studenten opgegeven verwachte score. Die punten zijn met de rode lijnstukken verbonden.
Als er geen zelfoverschatting en zelfonderschatting zou optreden en iedereen gemiddeld zijn testscore goed zou weten te voorspellen, zouden alle punten netjes op de diagonaal liggen.
Opgewipt been
Voor de punten op de groene lijn is dat ook zo, de kleine afwijkingen komen door de lage aantallen deelnemers in de onderzoekjes (voor de grafieken hierboven gaat het om respectievelijk om 65, 45 en 84 studenten).
Maar er is een goede statistische reden waarom de rode punten niet netjes langs de diagonaal liggen. Dat heeft ermee te maken dat proefpersonen die weten dat ze goed of erg goed scoren, maar weinig ruimte hebben aan de bovenkant van de schaal waarop ze hun relatieve positie moeten inschatten. En voor de slechtst presterende deelnemers, die dat van zichzelf wel aardig weten, is er minder ruimte om zich te onderschatten dan om zich te overschatten — wie vermoedt een nul te zullen halen, kan zichzelf moeilijk een nog lager cijfer geven. De vorm die je daarom mag verwachten is een liggend kruis, waarbij de diagonale groene lijn door een wat horizontaler liggende rode lijn gekruist wordt.
Het zuivere dunning-krugereffect zie je pas als het linkerbeen van het kruis ten opzichte van die uitgangspositie nog wat extra ‘opgewipt’ is.

Hoe komt het?
Kruger en Dunning gingen in hun artikel uit van een aantal voorspellingen. De eerste voorspelling was uiteraard het optreden van het effect zelf. Voorts stelden ze dat vooral een gebrek aan ‘metacognitieve’ vaardigheden (kennis over kennis) het effect verklaart. Zelfs als je de deelnemers uit het laagste kwart feedback geeft over hun feitelijke score of ze resultaten toont van andere deelnemers, blijft het effect optreden. Ze blijven zichzelf gemiddeld veel te hoog in de ranglijst zien, terwijl meer competente individuen na zulke feedback hun werkelijke positie beter weten in te schatten.
Volgens Kruger en Dunning zorgt het gebrek aan kennis over het specifieke onderwerp dat de ‘incompetente individuen’ fouten maken, maar datzelfde gebrek zorgt er ook voor dat ze niet goed kunnen inschatten hoe anderen het doen en hoe zij ten opzichte van hen scoren: ‘the double burden of incompetence’.
Tegenwerpingen
Er is wel kritiek gekomen op het artikel. De indeling in vier groepen zou wat onnodig en gekunsteld zijn, of de incompetente individuen zouden niet echt geloven dat ze bovengemiddeld scoren, of het zou toch vooral om ruis gaan. Vervolgonderzoeken van Dunning en anderen (Kruger is andere wegen ingeslagen) hebben veel van dat soort kritiek wel gepareerd.
Wat blijft staan is dat de oorspronkelijke grafieken de onderliggende data wel erg beknopt samenvatten en dat daardoor toch een misleidend beeld zou kunnen ontstaan. In het tijdschrift Numeracy publiceerde Edward Nuhfer, een geoloog die later meer in de onderwijskunde actief is geweest, twee artikelen waarin hij op basis van een groot aantal metingen probeert te laten zien wat er ‘achter de schermen’ van Dunnings grafieken gebeurt. Goede instrumenten om de relatie tussen zelfbeoordeling en de feitelijke prestaties op een bepaald vlak te onderzoeken zijn niet erg ruim voorhanden. Nuhfer en zijn coauteurs gebruiken de door hen ontwikkelde Science Literacy Concept Inventory (SLCI), een vragenlijst waarmee inzicht in de sleutelbegrippen van de wetenschap wordt getest (‘Wetenschap kan bepaalde soorten hypothesen testen met behulp van gecontroleerde experimenten’), en een bijbehorende test waarmee je zelfbeoordeling kunt meten, de Knowledge Survey van die SLCI (kortweg KSSLCI), die per vraag het zelfinzicht meet (‘Ik ken dit onderwerp voldoende om op getoetst te worden’). Een opzet die een betrouwbaarder zelfbeoordeling geeft dan het prikken op de ranglijst van Kruger en Dunning.
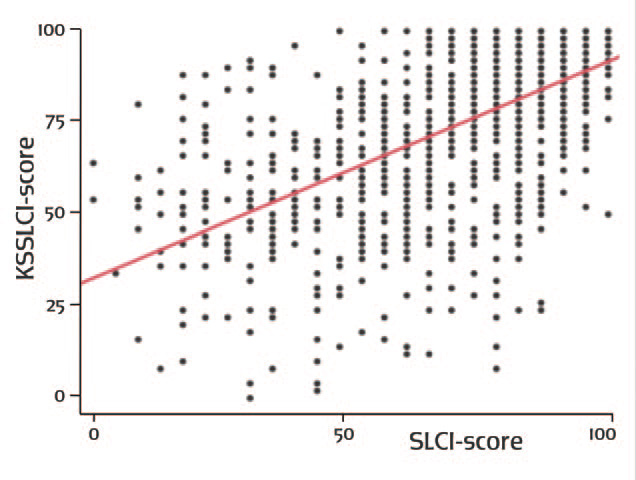
Als je de scores tegen elkaar uitzet, dus de kennis tegen de zelfkennis, ontstaat figuur 2. Wat opvalt is de grote spreiding in zelfbeoordeling bij proefpersonen die een even hoge testscore haalden — mensen die bijvoorbeeld tachtig procent van de vragen goed hadden, zaten tussen de tien en honderd procent in zelfinzicht.
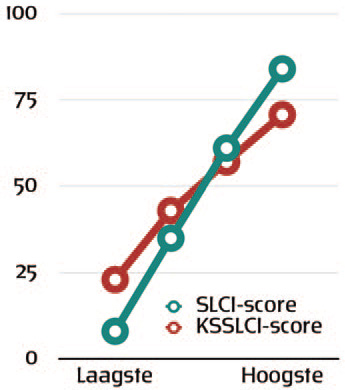
Als je hier dan een samenvatting van maakt à la Kruger en Dunning, zie je het bekende kruis weer opduiken (figuur 3).
Het ontbreken van een opwippend rood beentje doet vermoeden dat het dunning-krugereffect hier niet of amper optreedt. Ook zien we geen algemene zelfoverschatting, waarbij iedereen bovengemiddeld denkt te scoren. Volgens Nuhfer laat zijn onderzoek zien dat die ook helemaal niet optreedt zodra je instrument voor zelfbeoordeling goed in elkaar zit.
Vijf procent
In de data van Nuhfer zitten gegevens van eerstejaarsstudenten tot hoogleraren. Heel wat eerstejaarsstudenten halen een zeer hoge score terwijl hun zelfbeoordeling in overeenstemming lijkt te zijn met de kennis die je op hun opleidingsniveau mag verwachten. Bij de echte experts, de hoogleraren, liggen zelfbeoordeling en feitelijke score veel dichter bij elkaar, daar is minder variatie. In het hoogste kwart op basis van score zitten dus de echte experts maar ook een aantal al dan niet toevallig goed scorende beginnelingen. De gemiddelde zelfonderschatting die je in de dunning-krugergrafieken ziet bij het hoogste kwartiel kan mede daardoor verklaard worden. Op basis van zijn data schat Nuhfer dat de groep die slecht scoort én een veel te optimistisch beeld heeft, de echte ‘unskilled and unaware of it’, maar iets van vijf procent van het totaal uitmaakt.
Schakers en examinandi
Zoals veel psychologisch onderzoek zijn de experimenten van Kruger en Dunning uitgevoerd onder psychologiestudenten, zodat het weer enigszins de vraag is of de gevonden resultaten algemeen geldig zijn. In een overzichtsartikel uit 2011 geeft Dunning een opsomming van onderzoeken in real world settings, maar die zijn lang niet allemaal even overtuigend.
Young Joon Park en Luís Santos-Pinto onderzochten bijvoorbeeld of het effect optreedt bij pokeraars en schakers als je ze vraagt hoe hoog ze zullen eindigen in een toernooi. Bij poker zagen ze alleen algemene zelfoverschatting over de hele breedte, maar bij de schakers weken de voorspellingen van de minder sterke spelers over hun positie in het eindklassement duidelijk meer af van de werkelijkheid dan bij de sterke spelers. Dit lijkt een sterk voorbeeld van het dunning-krugereffect, want schakers hebben een objectieve maatstaf voor hun sterkte in de zogenaamde elo-rating. Maar er zit een luchtje aan dit deel van het onderzoek. Het probleem zit bij de gemiddelde spelers: daarvan zijn er veel meer dan van de schakers die strijden om de hoogste plaatsen. Gemiddelde spelers zitten er daardoor bij hun schatting veel makkelijker fors naast dan de sterkste spelers, voor wie een inschattingsfoutje en de vorm van de dag veel minder effect hebben op hun eindpositie. [zie hier voor een uitgebreidere bespreking]
Een beter voorbeeld dat Dunning aanhaalt is onderzoek uit 2009 naar de zelfbeoordeling van mensen die opgingen voor hun rijbewijs. Onder Finse proefpersonen zagen de onderzoekers een lichte neiging tot zelfoverschatting, maar bij een — wel veel kleinere — groep Nederlanders was het effect zeer sterk: degenen die zakten voor het examen overschatten zich gemiddeld meer dan degenen die waren geslaagd. De helft van de gezakte ondervraagden overschatte de eigen voertuigbeheersing, tegenover een derde van de geslaagden.
DAT Dunning en Kruger in 2000 een Ig Nobelprijs (een geestig bedoelde prijs voor lachwekkend maar serieus onderzoek) kregen voor hun artikel zal hebben bijgedragen aan de bekendheid van het effect. Het heeft ook wel iets ironisch, dat prutsers niet alleen prutsen maar het zelf ook niet door lijken te hebben. In 2017 werd het effect bij de uitreiking van de Ig Nobels ook bezongen in The Incompetence Opera — waarin uiteraard ook het peterprincipe verwerkt was.

Niet zo sterk
Er is genoeg reden om aan te nemen dat een dunning-krugereffect bestaat. Het is echter lang niet zo sterk als menigeen lijkt te geloven en een extreme wanverhouding tussen competentie en zelfbeeld komt maar bij een kleine groep voor. ‘Buiten het laboratorium’ is het bovendien niet zo makkelijk aan te tonen, het is alleen bij grote groepen betrouwbaar te meten, en het vergt een subtiel instrument voor zelfbeoordeling.
Van een echt dunning-krugereffect kun je volgens mij ook alleen spreken als deelnemers in principe een zelfde waarheidsbegrip hebben. De deelnemers die zakten voor hun rijexamen zijn het misschien niet helemaal eens met hoe hun rijvaardigheid beoordeeld is, maar ze zullen niet snel denken dat je bij een rood verkeerslicht mag doorrijden. Bij gevoel voor humor is dat alweer wat ingewikkelder.
In de praktijk wordt er nogal snel iets als een dunning-krugereffect geduid. Het tegenspreken van gevestigde wetenschap kan voortkomen uit een gebrekkig inzicht in de materie, maar kan ook een ideologische grond hebben. Als antivaxers in een onderzoek beweren meer verstand te hebben van vaccinaties dan erkende experts, lijkt mij dat geen goed voorbeeld van het effect. Dan speelt er eerder iets als motivational reasoning. Als ze zeggen het beter te weten dan virologen komt dat veeleer doordat ze expertise überhaupt op een andere schaal meten, en dat ze deskundigen als bewuste leugenaars in dienst van BigPharma zien en dus niet als onafhankelijke experts erkennen. Maar ik kan er helemaal naast zitten — stellig beweren dat je verstand hebt van het dunning-krugereffect is natuurlijk een beetje vragen om moeilijkheden.
Literatuur
Kruger J, Dunning D. Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of Personality and Social Psychology 1999;44:247–296, PMID 10626367.
Dunning, D. Chapter five — the Dunning–Kruger effect: on being ignorant of one’s own ignorance. Advances in Experimental Social Psychology 2011; 44:247–296.
Nuhfer E, Cogan C, …, Wirth K. Random number simulations reveal how random noise affects the measurements and graphical portrayals of self-assessed competency. Numeracy 2016; 9:1.
Nuhfer E, Fleisher S, …, Gaze E. Random number simulations reveal how random noise affects the measurements and graphical portrayals of self-assessed competency. Numeracy 2017;10:1.
Park YJ, Santos-Pinto L. Overconfidence in tournaments: evidence from the field. Theory and Decision 2010;69:143–166.
Motta M, Callaghan T, Sylvester S. Knowing less but presuming more: Dunning-Kruger effects and the endorsement of anti-vaccine policy attitudes. Social Science & Medicine 2018;211:247–281, PMID 29966822.



